
Технология из Гарри Поттера дошла до наших дней. Теперь для создания полноценного видео человека достаточно одной его картинки или фотографии. Исследователи машинного обучения из «Сколково» и центра Samsung AI из Москвы опубликовали свою работу о создании такой системы, вместе с целым рядом видео знаменитостей и предметов искусства, получивших новую жизнь.

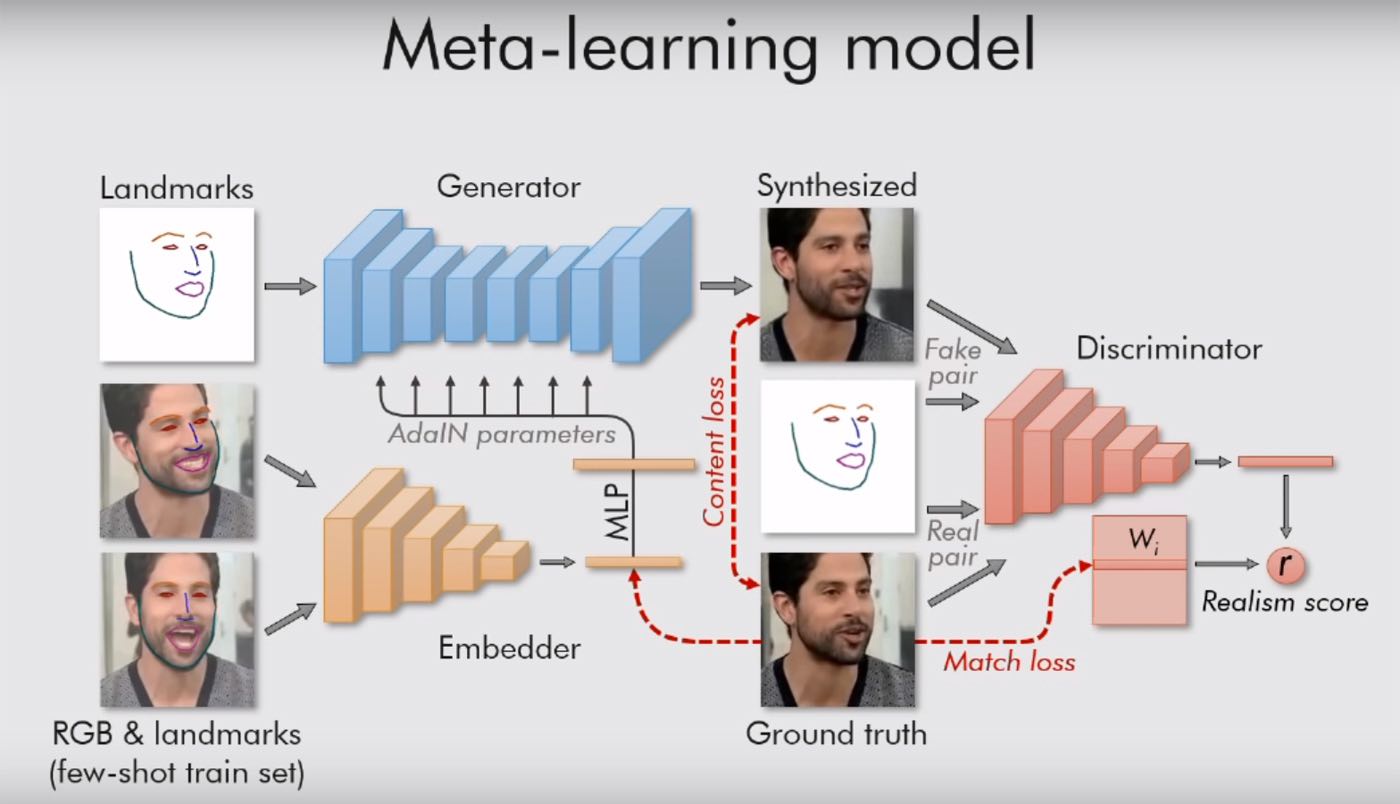
Текст научной работы можно почитать тут. Там всё довольно интересно, с массой формул, но смысл прост: их система руководствуется «ориентирами», достопримечательностями лица, вроде носа, двух глаз, двух бровей, линии подбородка. Так она мгновенно улавливает, что человек собой представляет. И потом может переносить всё остальное (цвет, текстуру лица, усы, щетину и прочее) на любое другое видео человека. Адаптируя старое лицо к новым ситуациям.
Разумеется, это пока работает только на портретах. Модели нужен только один человек, с лицом, повернутым к нам, чтобы у него было хотя бы видно оба глаза. Тогда система может делать с ним что угодно, передавать ему любую мимику. Достаточно дать ей подходящее видео (с другим человеком с головой примерно в том же положении).
Ранее ИИ уже научился делать Deepfake, и интернет-пользователи вдоволь поиздевались над знаменитостями, вставляя их лица в порно и делая мемы с Николасом Кейджем. Но для этого им приходилось тренировать алгоритмы мегабайтами (а лучше – гигабайтами) данных, находить как можно больше изображений и видео с лицами знаменитостей, чтобы выдать более-менее пристойный результат. Сам создатель Deepfakes говорил, что на компиляцию одного короткого ролика у него уходит 8-12 часов. Новая система генерирует результат моментально, а на входе ей достаточно одной картинки.
С предыдущей системой мы никогда бы не смогли посмотреть на живую Мону Лизу, у нас есть только один её ракурс. Теперь, с алгоритмами, работающими по ориентирам, это становится возможным. Идеала не достичь, но уже что-то близко.
В работе московских исследователей также используется генеративно-состязательная сеть. Две модели алгоритма сражаются друг с другом. Каждая пытается обмануть оппонента, и доказать ему, что то видео, которое она создает – настоящее. Так достигается определенный уровень реализма: картинка человеческого лица не выпускается «в свет», если модель-критик не уверена в её подлинности более чем на 90%. Как говорят авторы в своей работе, в изображениях регулируются десятки миллионов параметров, но за счет такой системы, работа кипит очень быстро.
Если картинок несколько, результат улучшается. Опять же, проще всего получается работать со знаменитостями, которые уже сняты со всех возможных ракурсов. Для достижения «идеального реализма» нужны 32 снимка. В этом случае сгенерированные ИИ фото в невысоком разрешении будут неотличимы от настоящих фото человека. Нетренированные люди на этом этапе уже не способны выявить фейк – возможно, шансы остаются у экспертов или у близких родственников «подопытного» со всех этих изображений.
Если фото или картинка только одна, итог пока не всегда самый лучший. Увидеть артефакты на видео, когда голова находится в движении, можно без особых проблем. Сами исследователи говорят, что их самое слабое место – взгляд. Модель, основанная на ориентирах лица, пока не всегда понимает, как и куда человек должен смотреть.
По материалам habr. Компания Pochtoycom.