
Возможность заставить компьютеры читать текст уже довольно давно стала обычным явлением в повседневной жизни. Мы привыкли слышать металлические голоса в своих смартфонах, читая монотонные сводки погоды за день и заголовки. Однако в последнее время технология искусственного голоса переживает возрождение качества вывода. Создатели контента теперь имеют доступ не только к традиционным сервисам TTS (преобразование текста в речь), но и к программному обеспечению для озвучивания, подобному человеческому, которое имитирует естественную речь. Футурист Рэй Курцвейл однажды предсказал в 2005 году, что соотношение цены и качества синтезаторов речи будет экспоненциальным, что позволит создателям не только существенно снизить затраты на производство, но и демократизировать доступ к ранее эксклюзивным инструментам обработки звука.
Не будет упущением сказать, что мы уже достигли или близки к достижению будущего, предсказанного Курцвейлом, с машиночитаемыми аудиокнигами и виртуальными влиятельными лицами. Однако, прежде чем мы придем к такому суждению о настоящем, давайте оглянемся на технологические достижения, которые позволили нам вступить в этот новый период роста TTS.
Истоки и методология
В основе технологии клонирования голоса лежит синтез речи с использованием механизма TTS. На самом деле TTS – это технология, созданная десятилетиями и восходящая к 1960-м годам, когда такие исследователи, как Норико Умеда из Электротехнической лаборатории и физик Джон Ларри Келли-младший, разработали первые версии компьютерного синтеза речи. Любопытно, что именно демонстрация синтезатора Келли, воссоздающая песню «Дейзи Белл», вдохновила Стэнли Кубрика и Артура Кларка на использование электронного синтезатора в кульминации фильма «2001: Космическая одиссея».
В прошлом, до разработки моделей TTS на основе нейронных сетей, которые мы используем сегодня, было два основных подхода к клонированию голоса: конкатенативный TTS и параметрический TTS. Оба подхода пытались максимизировать естественность и разборчивость речи, наиболее важные характеристики синтеза речи.
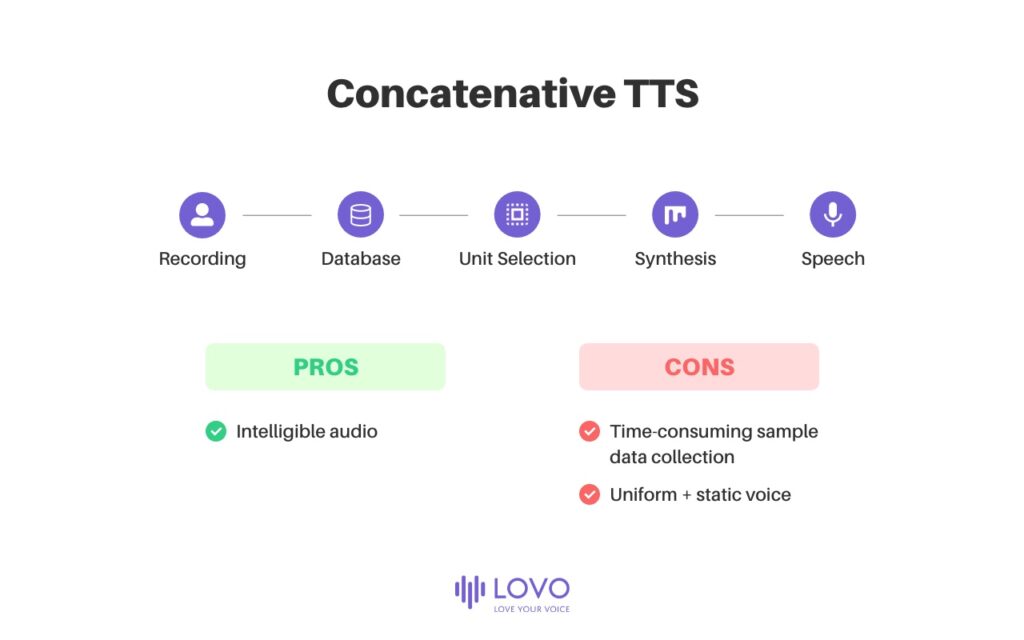
Конкатенативный TTS описывает процесс накопления базы данных коротких звуковых образцов, которые могут варьироваться от 10 миллисекунд до 1 секунды, которыми пользователь затем будет напрямую манипулировать для объединения и генерации определенных звуковых последовательностей. Эти последовательности затем можно было сформировать для создания слышимых и разборчивых словесных предложений, но из-за единообразной и статической природы последовательностей в конкатенативных TTS не хватало фонетических вариаций и идиосинкразий, которые делали речь естественной и эмоционально выразительной. Кроме того, создание наборов данных, необходимых для полнофункциональной конкатенативной TTS, занимало невероятно много времени.
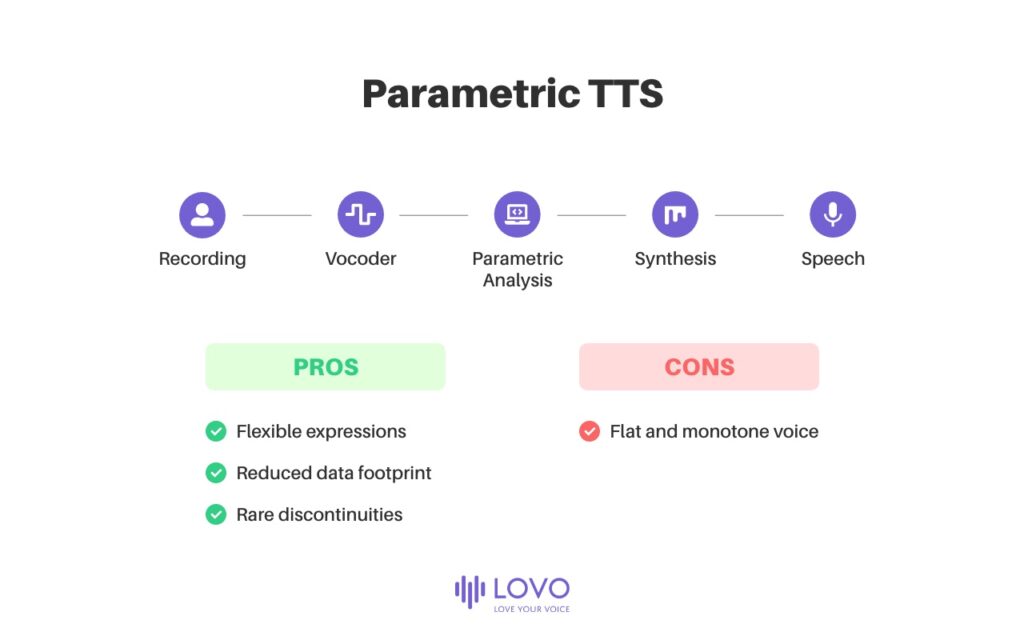
Параметрическая TTS использует статистические модели для прогнозирования речевых вариаций параметров, из которых состоит речь. После того, как голосовой актер записан, читая сценарий, исследователь может обучить генеративную модель, чтобы изучить конкретные распределения записанных звуковых параметров (акустика, частота, амплитудный спектр, просодика, спектрограмма) и лингвистику текста, а затем использовать TTS. для воспроизведения искусственной речи с параметрами, аналогичными исходной записи голоса (вокодирование). В конце концов, это означает, что объем данных значительно сокращен по сравнению с конкатенативным TTS, а модель вывода гораздо более гибкая в адаптации конкретных вокальных выражений и акцентов. TTS также «сглаживает» запись, делая прерывания звука редкими, но, напротив, делает речь более плоской и монотонной, что позволяет легко отличить ее от естественного голоса.
Даже с учетом их ограничений, именно разработка таких методологий TTS с использованием линейного прогнозирующего кодирования (LPC) позволила производить культовые синтезаторы речи для потребителей, такие как тот, который использовал Стивен Хокинг в 1999 году, и игры, подобные Milton.
AI Powered TTS (LOVO)
Сегодня TTS переживает стремительный новый этап инноваций, и в ней преобладает подход Deep Neural Network (DNN). Используя искусственный интеллект и алгоритмы машинного обучения, метод DNN пытается исключить любое вмешательство человека в процесс клонирования голоса, полностью автоматизируя такие задачи, как сглаживание и генерация параметров. Конечно, наука еще не достигла стадии полной автоматизации, но мы к ней приближаемся.
Некоторые из первых пионеров подхода DNN включают Wavenet от Google Deepmind, параметрическую модель авторегрессии, построенную с помощью случайных сверток, и Deepvoice от Baidu, в котором используется сверточная нейронная сеть. Все эти сбивающие с толку технические описания не помогают нам понять стадию развития, к которой мы сейчас подошли: с минимальными звуковыми образцами мы теперь можем воссоздать человеческие озвучки с искусственным интеллектом для ускорения создания контента.
Не верите нам? Посмотрите наши демонстрации:
По материалам блога Joon Chang