Предыдущий год стал годом невероятного прогресса в исследованиях синтетической речи. Созданные с помощью новых методов искусственного интеллекта, клонированные синтетические голоса теперь практически неотличимы от реального голоса.
Было много проектов с предложения технологии синтетической речи для различных отраслей промышленности с открытым исходным кодом, таким как Nvidia/Tacotron2 или Tensorspeech/TensorflowTTS. Мы видим, как компании, такие как Wellsaid Labs, добиваются успеха в корпоративной индустрии L&D, которая является крупнейшим сегментом рынка озвучивания в США, занимающим 24,3% доли рынка. Мы также видим такие компании, как Replica Studios и Sonantic, которые занимаются более сложными отраслями, такими как производство игр, которые требуют гораздо большей эмоциональной выразительности. И, конечно же, 15.ai позволяет создавать голосовые мемы с использованием любимых в Интернете персонажей мультфильмов и игр. Если вам интересно, да, они составляют конкуренцию LOVO, но пока никто из нас не представляет реальной угрозы друг другу.
Все обещания, показанные до сих пор, являются фантастическими. Однако для того, чтобы технология синтетической речи изменила парадигму производства голосового контента, нам нужно достичь того, что в LOVO называют общим интеллектом для синтетической речи.
Общий интеллект в синтетической речи: что это такое?
Мы видим развитие синтетической речи в три этапа: естественное произнесение, просодический контроль и контроль тембра.
Естественное произношение: на этом этапе основная цель системы синтеза речи состоит в том, чтобы научиться произносить речь естественным образом, как человек, с полным сходством с голосом исходного говорящего с максимально возможной точностью воспроизведения звука. Исследования в этой области ведутся десятилетиями с использованием конкатенативного синтеза речи. В 2016 году произошел крупный прорыв с WaveNet от Deepmind, а в 2017 году с Google Tacotron, продемонстрировав огромные улучшения в естественности и сходстве. В последующие годы появилось множество инноваций, направленных на улучшение этих результатов с упором на масштабируемость и стабильность. Например, технология Waveglow от Nvidia нацелена на ускорение WaveNet на несколько порядков для реальных приложений. Появились многочисленные методы точной настройки, которые позволили сократить потребность в данных для обучения систем синтеза речи с часов до минут и даже секунд.
К середине 2020 года научные круги и промышленность вместе в значительной степени преодолели этот этап, поэтому сейчас вы видите так много компаний, предлагающих аналогичные технологии клиентам.
Просодический контроль: Просодия по определению «касается тех элементов речи, которые не являются отдельными фонетическими сегментами, но являются свойствами слогов и более крупных единиц речи, включая лингвистические функции, такие как интонация, ударение и ритм». Здесь мы видим усилия по совершенствованию систем синтеза речи для обеспечения просодической управляемости конечных пользователей. Теперь мы можем вводить в модели ИИ просодическую информацию, такую как интонация и ритм, а также текстовые и аудиоданные во время обучения. В LOVO мы даже можем заставить наш ИИ петь! Даже если первоначальный оратор никогда не пел, мы можем заставить его спеть любую песню с просодическим контролем. Мы также можем клонировать голоса певцов, чтобы петь песни, которые они никогда раньше не пели. Исследования в этой области все ещё продолжаются, и для того, чтобы вывести эти улучшения на рынок, все ещё требуется много инженерных решений для обеспечения стабильности.
Контроль тембра: тембр определяется как всё, что однозначно определяет чей-то голос, кроме просодии. Вы можете представить себе скрипку и фортепиано, играющие одну и ту же высоту в одном и том же ритме, но, очевидно, звучащие по-разному.
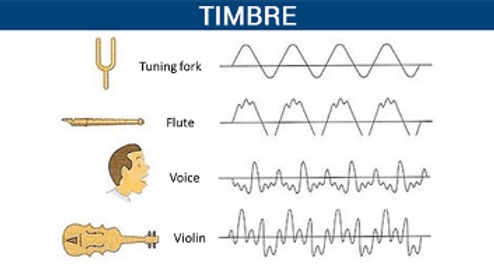
Вы, возможно, заметили, что это определение является довольно открытым, и для этого есть веская причина. Характеристики человеческой речи, отличные от просодии, чрезвычайно трудно определить семантически. Если вы спросите 10 человек, как они определяют «ржавый» голос, вы можете получить 10 разных определений. И наоборот, если вы попросите 10 человек описать чей-то голос после его прослушивания, вы также можете получить совсем другие прилагательные.
В некоторой степени мы достигли управления тембром, идеально клонировав чей-то голос и связав эту тембровую информацию с идентичностью говорящего. Следовательно, теперь мы можем отделить просодическую информацию от информации о содержании и тембре. Некоторые исследования продолжаются в отношении сопоставления тембра говорящего неконтролируемым образом для категоризации и интерполяции, чтобы изобрести совершенно новые (действительно синтетический голос, который звучал как бы на полпути между Обамой и Трампом). Однако ни одна из этих попыток не способна семантически и объективно определить различные классы тембра, которые могут быть легко интерпретированы людьми.
Если мы сможем добиться полного интерпретируемого управления тембром, мы сможем вводить команды с несколькими параметрами тембра, такими как «Я хочу, чтобы непринужденный, уверенный, хриплый русский голос в дружелюбном тоне, в возрасте 50 лет, использовался для информационных бюллетеней» и AI сразу построит этот голос для вас.
Так как же нам достичь этой последней стадии контроля тембра?
Нужны данные. МНОГО данных.
Это то, над чем мы сейчас работаем в LOVO.
До скорой встречи!
По материалам блога Charlie Choi