В одной из более ранних статей мы рассказывали, как создать DeepFake самостоятельно. В этой статье приводится краткий обзор решений, которые можно использовать для создания DeepFake видео, их достоинства и недостатки.
Из существующих подходов к созданию DeepFake можно выделить следующие:
- Архитектура основанная на схеме кодер-декодер
- Генеративно-состязательные сети (GAN)
Энкодер-декодер архитектура
К данному подходу можно отнести методы генерации основанные на автоэнкодерах. Их объединяет использование пиксельных (изображение на входе попиксельно сравнивается с изображением на выходе, оптимизируется MSE,MAE и т.п. функции) потерь, что определяет достоинства и недостатки и данной схемы. Плюс в том, что автоэнкодеры относительно просто (в сравнении с GAN) обучать. Минусом является то, что оптимизация по пиксельным метрикам не позволяет добиться фотореалистичности, сравнимой с GAN. Со схемой с двумя декодерами можно ознакомиться здесь. Её архитектура представлена на рисунке ниже.
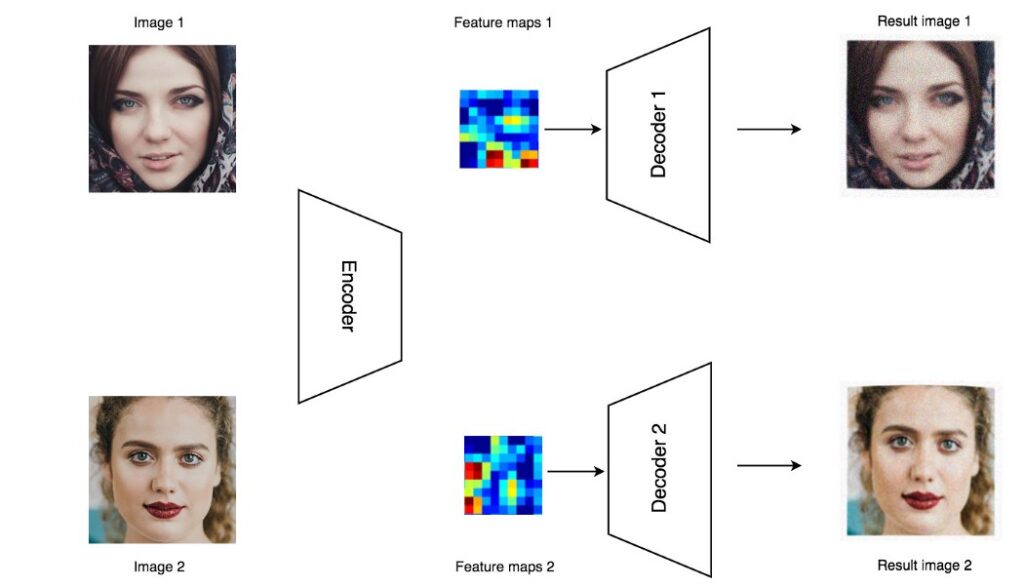
Идея данного подхода в следующем: используется энкодер-декодер схема, при этом энкодер один, а декодеров используется несколько. Каждый декодер может создавать изображения только одного человека. Данный подход, «каждому человеку – отдельный декодер», ограничивает использование данной модели.
Недостатком является обучение отдельного декодера для каждого нового человека которого мы хотим сгенерировать. Для некоторых сценариев это не критично, например при производстве рекламных роликов это не будет проблемой. Но, для приложения, где пользователь хочет создать DeepFake со своим участием, такая схема не подойдёт. Вряд ли кому-то понравится ждать несколько часов, пока под него обучается отдельный декодер. К достоинствам данной модели можно отнести её относительную компактность. В отличие от других подходов, не нужно создавать и обучать дополнительные сетки для кодирования внешности.
Condtional Autoencoder
Идея данного подхода в следующем: на вход энкодера подается изображение и вектор атрибутов. На вход декодера поступает вектор размерности latent_dim являющейся выходом энкодера и вектор атрибутов. Атрибутом может быть любой признак характеризующий изображение, например наличие/отсутствие улыбки (и других эмоций), повернута голова вправо или влево, внешность человека и т.п. Т.к. вектор атрибутов поступает в декодер напрямую, энкодеру нет смысла извлекать из входного изображения эту информацию. Т.е. например, если в atrributes vectors задать внешность человека, то энкодер будет кодировать только свойства изображения не связанные с внешностью, такие как поворот и наклон головы, эмоции, освещение и т.п. Схема представлена на рисунке ниже.
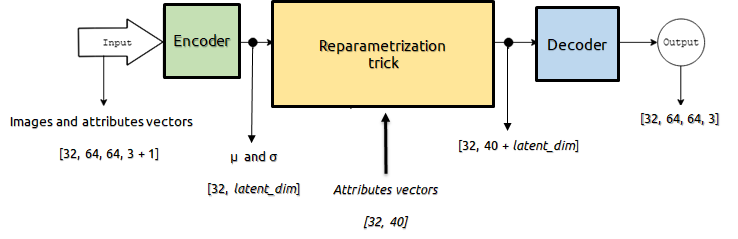
И если к выходу энкодера добавить atrributes vectors другого человека, декодер восстановит картинку, где поворот головы и эмоции будут соответствовать исходному изображению, а внешность будет от другого человека. В этой схеме не требуется обучать отдельный декодер для каждого нового человека, которого мы хотим генерировать, т.к. замена внешности реализуется изменением atrributes vectors подаваемого в декодер. Примеры восстановленных изображений с помощью данного подхода можно увидеть на рисунке ниже.

Изображения разбиты по парам, справа – оригинальные изображения лиц, слева – восстановленные автоэнкодером. Хорошо виден недостаток присущий автоэнкодерам: «замыленность», недостаточная резкость восстановленных изображений. Можно попробовать доработать восстановленные изображения, повысить резкость и т.п. но существует подход изначально лишенный этих недостатков.
Conditional GAN
В GAN генератор получает на вход случайный вектор, и возвращает сгенерированное изображение. В DeepFake изображение должно обладать рядом заданных свойств: внешность одного человека, поворот головы и эмоции другого. Сравнение GAN и Conditional GAN архитектур представлено на рисунке ниже.
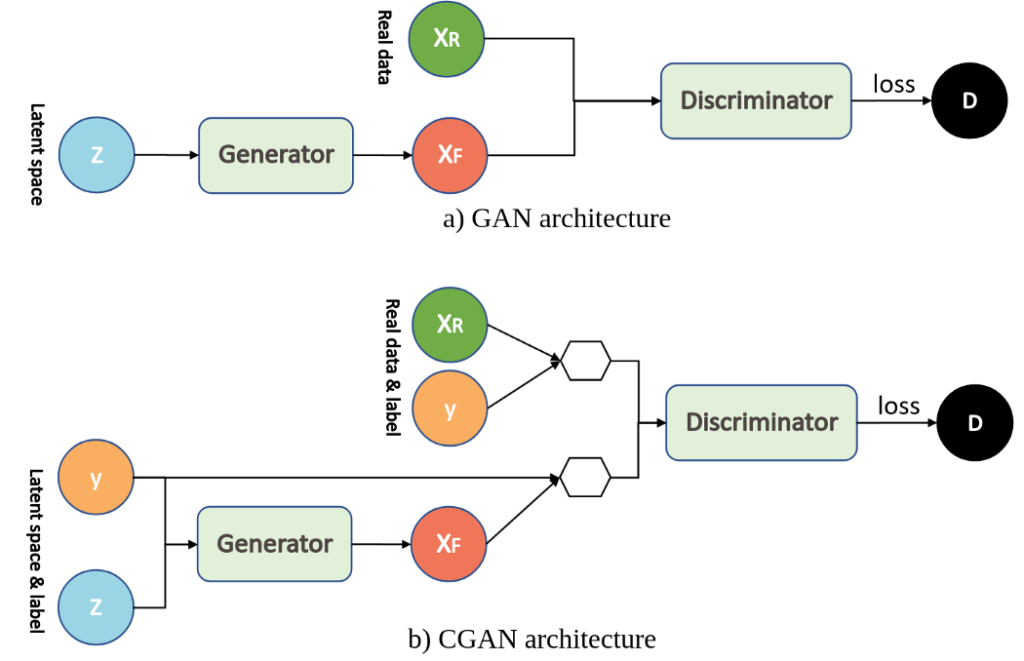
В классическом GAN, генератор получает на вход случайный вектор и генерирует изображение. При этом изображение является случайным, т.е. неизвестно сгенерируется женщина или мужчина, будет смотреть прямо или направо, будет улыбаться или грустить. В Conditional Gan на вход генератору подается два вектора: случайный вектор Z и вектор атрибутов (на приведенной схеме обозначен label). Дискриминатор получает на вход изображение и соответствующий вектор атрибутов. В процессе обучения генератор учится создавать не только реалистичные изображения, но и соответствующие вектору атрибуты. Результаты использования Conditional GAN представлены на рисунке ниже.

Изображения сгруппированы по парам: слева – сгенерированные, справа – оригинал. В attributes vectors задаются поворот и наклон головы, эмоции и внешность человека. Xорошо видна способность GAN генерировать фотореалистичные изображения. Если сравнить сгенерированные картинки с рассмотренными ранее результатами автоэнкодеров, создается впечатление, что GAN выигрывает в одни ворота. Но не нужно забывать, что конечной целью DeepFake является генерация не одной картинки, а видео ролика. Позже, будет подготовлена статья, как перейти от генерации отдельных изображений к созданию видео.
Сборка DeepFake на основе GAN выглядит следующим образом:
Видео получается на первый взгляд хорошо. Но, сгенерированные изображения почти не повторяют мелкую моторику. Лёгкие покачивания из стороны в сторону — вообще не повторяет. На следующем ролике, у третьего лица слева, 4-6 секунды, подбородок движется с мелкими поворотами, а глаза с носом движутся плавно. Создаётся впечатление, что это маска.
Датасеты с лицами в 1024*1024 были взяты на github:
github.com/NVlabs/ffhq-dataset
github.com/switchablenorms/CelebAMask–HQ
В настоящий момент продолжается развитие проекта. Планируется много доработок, в первую очередь – увеличение разрешения, отработка сцен с сложным освещением.
По материалам habr.