
Свободно доступные алгоритмы для синтеза речи способны обмануть как алгоритмы для идентификации человека по голосу, так и обычных людей, выяснили американские исследователи. Они использовали два алгоритма, которые на основе коротких записей голоса создают новую речь, «произнесённую» тем же человеком. Статья опубликована на arXiv.org.
Наряду с распознаванием лиц, некоторые сервисы применяют алгоритмы для идентификации голоса. Например, умные колонки Яндекса умеют узнавать голос владельца, чтобы учитывать рекомендации только для его запросов, а WeChat позволяет войти в аккаунт с помощью голоса. Разработчики этих и других сервисов исходят из того, что человеческий голос уникален, поэтому его можно использовать как надёжное доказательство, что система разговаривает именно с хозяином аккаунта или устройства. Но алгоритмы синтеза речи, особенно нейросетевые, быстро развиваются, и есть как открытые алгоритмы, так и коммерческие сервисы, позволяющие по довольно небольшому объёму записей (относительно того, который используется для базовой модели) создать модель, качественно копирующую голос конкретного человека. И если алгоритмы распознавания лиц зачастую учитывают объём, поэтому обмануть их простым дипфейком не получится, то для голоса нет возможности учесть какой-то подобный дополнительный фактор.
Исследователи из Чикагского университета под руководством Эмили Венгер (Emily Wenger) решили оценить прогресс алгоритмов копирования голоса и проверить их работу. Выбранная модель атаки предполагает, что у злоумышленника есть доступ к образцам голоса жертвы в виде публично доступных аудио или видеозаписей, или возможность пообщаться с ним, чтобы записать речь. Используя эти данные, он может дообучить голосовую модель, чтобы та синтезировала желаемый голос. При этом авторы сделали реалистичное ограничение — для формирования копирующей модели у злоумышленника есть не более пяти минут записей. Также они решили использовать только публично доступные алгоритмы. Исследователи выбрали два таких алгоритма: SV2TTS и AutoVC. Для обучения моделей авторы использовали записи речи 90 людей из трёх публичных датасетов: VCTK, LibriSpeech и SpeechAccent.
Исследователи проверяли качество синтезированных записей речи на открытом программном обеспечении Resemblyzer, а также коммерческих сервисах: Microsoft Azure, WeChat и Amazon Alexa. Лучше всего себя показали модели, обученные на базе SV2TTS и датасета VCTK. Для Resemblyzer доля успешных атак составила 50,5 ± 13,4%, для Azure — 29,5 ± 3,2%. Поскольку у WeChat и Alexa нет открытого API, их исследователи тестировали иначе. Они привлекли 14 добровольцев, которые зачитывали текст для обучения модели, а затем проверяли систему с помощью синтезированных SV2TTS аудиозаписей — пытались войти в аккаунт WeChat или просили Alexa выполнить персонализированную команду. 9 из 14 добровольцам удалось войти в WeChat (всего было 6 фейковых аудиозаписей), а Alexa так или иначе удалось обмануть всем 14 добровольцам, в среднем успешность составила 62,2%.
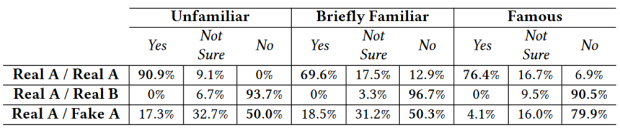
После оценки алгоритмов, исследователи проверили людей, пригласив 200 добровольцев. Им давали прослушать пары аудиозаписей и спрашивали, кто их произнёс: один человек или разные. В парах было три варианта, о которых участники не знали: две записи от одного человека; две от разных; запись от одного человека и подделывающей его голос модели. Выяснилось, что в половине случаев добровольцы не сумели различить настоящий голос от поддельного. Им также давали записи известных людей и поддельные образцы их речи. В таком случае обман не смогли распознать только в 20% случаев.
По словам исследователей, инструменты имитирования голоса могут нанести серьезный ущерб в различных условиях:
«Они могут обойти голосовые системы аутентификации, автоматические телефонные линии в банках, службы входа в мессенджеры, такие как WeChat. Это также приведет ко взлому служб, предоставляющих доступ к устройствам Интернета вещей, например цифровых помощников Amazon Alexa или Google Home»
Ученые добавили, что голосовые дипфейки также могут напрямую атаковать конечных пользователей, дополняя традиционные фишинговые мошенничества знакомым человеческим голосом.
В сентябре мошенники использовали дипфейк Олега Тинькова для рекламы поддельного сайта «Тинькофф Инвестиции».
В марте американская полиция арестовала женщину за травлю подростков с помощью сгенерированных фото.
По материалам N + 1. Автор Григорий Копиев